To evaluate elastic quotas in a real world operating system environment, we implemented a prototype of our elastic quota system in Solaris 9, the latest operating system release1 from Sun Microsystems. We chose Solaris because it is widely used in large production environments such as the file servers on which elastic quotas would operate. We present some experimental results using our prototype EQFS and rubberd implementations. We compared EQFS against Solaris 9 UFS [2], the most popular file system used on Solaris servers. We also measured the impact of rubberd on a running system.
We conducted all experiments on a Sun-Fire 480R multiprocessor system with four 750 MHz UltraSPARC-III CPUs and 4 GB of RAM, running Solaris 9. We believe this is a moderate size machine for the type of large file servers that elastic quotas will be useful on. Although such installations will probably include RAID arrays or SAN products, we focused on the native disks that were in the machine; this helped us to analyze the results without worrying about interactions with other storage systems. For all our experiments, we used a local UFS file system installed on a Seagate Cheetah 36LP disk with 36 GB capacity and 10000 rpm. UFS includes optional logging features used in some installations that enable a form of journaling that logs meta-data updates to provide higher reliability guarantees. We considered both UFS and UFS logging (LUFS) in our experiments. For each experiment, we only read, wrote, or compiled the test files in the file system being tested. All other user utilities, compilers, headers, and libraries resided outside the tested file system. Unless otherwise noted, all tests were run with a cold cache by unmounting all file systems that participated in the given test after the test completed and mounted the file systems again before running the next iteration of the test.
We report experimental results using both file system benchmarks and real applications. Sections 5.1 and 5.2 describe the file system workloads we used for measuring EQFS and rubberd performance, respectively. Sections 5.3 shows results for three file system workloads comparing EQFS to UFS to quantify the performance overhead of using EQFS. Section 5.4 shows results quantifying the impact of rubberd's actions on a running system: reclaiming storage, building its database, etc.
To measure EQFS performance, we stacked EQFS on top of UFS and compared its performance with native UFS. We measured the performance of four file system configurations on a variety of file system workloads: UFS without logging (UFS), UFS with logging (LUFS), EQFS on top of UFS (EQFS/UFS), and EQFS on top of LUFS (EQFS/LUFS). We used three file system workloads for our experiments: PostMark, a recursive find, and a compilation of a large software package, the Solaris 9 kernel.
Because the default PostMark workload is too small, we configured PostMark to perform 5000 transactions starting with an initial pool of 2500 files with sizes between 8 KB and 64 KB, matching file size distributions reported in file system studies [29]. Previous results obtained using PostMark show that a single PostMark run may not be indicative of system performance under load because the load is single-threaded whereas practical systems perform multiple concurrent actions [28]. Therefore, we measured the four file systems running 1, 2, 4, and 8 PostMark runs in parallel. This not only allows us to conservatively measure EQFS's performance overhead, but also evaluate EQFS's scalability as the amount of concurrent work done increases. The latter is even more important than the former, since raw speed can be improved by moving to a larger machine, whereas poorly-scaling systems cannot be easily helped by using larger machines.
To evaluate rubberd, we measured how long it took to build its nightly elastic files log and use it for cleaning elastic files. The rubberd log we used contains the names of elastic files and lstat(2) output. To provide realistic results on common file server data sets, we used a working set of files collected over a period of 18 months from our own production file server. The working set includes the actual files of 121 users, many of whom are software developers. The file set includes 1,194,133 inodes and totals over 26 GB in size; more than 99% of the file set are regular files. 24% of the users use less than 1 MB of storage; 27% of users use between 1-100 MB; 38% of users use between 100 MB-1 GB of storage; and 11% of users consume more than 1 GB of storage each. Average file size in this set is 21.8 KB, matching results reported elsewhere [20]. We treated this entire working set as being elastic. Previous studies [23] show that roughly half of all data on disk and 16% of files are regeneratable. Hence by treating all files as elastic, we are effectively modeling the cost of using rubberd on a disk consuming a total of 52 GB in 7.5 million files. Using EQFS mounted on LUFS, we ran three experiments with the working set for measuring rubberd performance: building the elastic files log, cleaning elastic files using the log, and cleaning elastic files while running a file system workload.
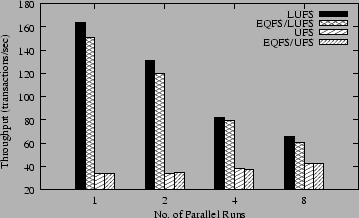
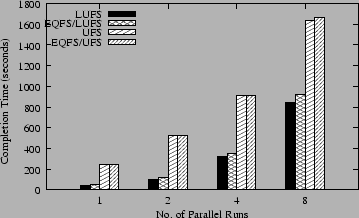
The following two figures show the results for running PostMark on each of the four file systems. Figure 2 shows the total throughput of the system and Figure 3 shows the total time it takes to complete all of the runs. The results for LUFS show that EQFS incurs less than 10% overhead over LUFS, with the EQFS/LUFS throughput rate and completion time being within 10% of LUFS. The results for UFS are even better, showing that EQFS incurs hardly any overhead, with the EQFS/UFS throughput rate and completion time being within 1% of UFS. These results show that EQFS's overhead is relatively modest even for a file system workload that stresses some of the more costly EQFS file operations.
EQFS exhibits higher overhead when stacked on LUFS versus UFS in part because LUFS performs better and is less I/O bound than UFS, so that any EQFS processing overhead becomes more significant. LUFS logs transactions in memory, clustering meta-data updates and flushing them out in larger chunks than regular UFS, resulting in higher throughput and lower completion time than regular UFS for PostMark. However, UFS scales better than LUFS, as evident by the fact that the total throughput rate for UFS increases slightly with more parallel PostMark runs whereas the throughput rate for LUFS decreases significantly. More importantly, the results show that EQFS scales with the performance of the underlying file system and in no way impacts performance adversely as the amount of concurrent work done increases.
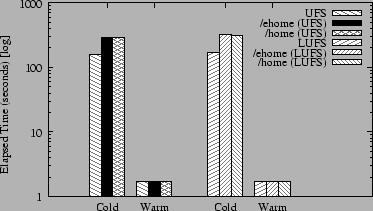
Figure 4 shows the results for running the recursive find benchmark on each of the file systems. We show results for running the benchmark with both cold cache and warm cache. The cold cache results show that EQFS incurs roughly 80% overhead in terms of completion time when stacked on top of UFS or LUFS, taking about 80% longer to do the recursive scan than the native file systems. The high EQFS overhead is largely due to the frequent READDIR operations that are done by the recursive scan. Using a cold cache with the recursive scan, each READDIR operation requires going to disk to read the respective directory block. Because EQFS must merge both persistent and elastic directories, READDIR requires two directory operations on the underlying file system. This causes twice as much disk I/O as using the native file system to read directories, resulting in a significantly higher completion time. This is compounded by the fact that most FFS-like file systems such as UFS make an attempt to cluster meta-data and data together on disk; UFS does not necessarily place the two sister directories close to each other on disk, hence reading the two directories not only causes multiple I/O requests, but also causes the disk to seek more, which slow overall performance. Overall the recursive find benchmark is not representative of realistic file workloads, but provides a measure of the worst-case overhead of EQFS as READDIR is the most expensive EQFS operation.
In this test all files found were located under /persistent. This meant that looking up files via /home found the files in the primary directory, whereas when looking them up via /ehome, the files were logically located in the sister directory and EQFS had to perform two LOOKUP operations to find those files. Nevertheless, Figure 4 shows that the overhead of looking up those files with an extra LOOKUP was small: 4.2% when mounted on LUFS and only 0.1% when mounted on top of UFS.
When using a warm cache, Figure 4 shows that EQFS incurs essentially no overhead versus the native file system when stacked on top of either UFS or LUFS. For all file systems, the recursive find took less than two seconds to complete, roughly two orders of magnitude faster than when using a cold cache. Like other Solaris file systems, our EQFS implementation utilizes the Solaris Directory Name Lookup Cache (DNLC). The warm cache results illustrate the full benefits of caching. Since the directory contents are already merged and cached, EQFS does not spend additional time merging directories, resulting in negligible performance overhead. There is also no difference in EQFS performance when using /home versus /ehome since LOOKUP requests are satisfied from the cache and EQFS does not call the underlying file system.
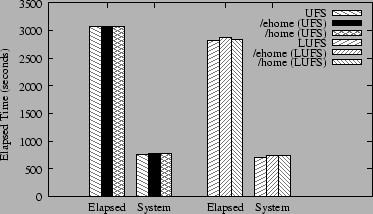
Figure 5 shows the results for running the Solaris compile on each of the file systems. Results are reported in terms of elapsed time and system time. Although we do not report user time, we note that the sum of user and system time is higher than elapsed time, due to the parallel nature of the build and the multiprocessor machine used. The results show that EQFS incurs almost no overhead in completion time when stacked on top of UFS or LUFS, taking less than 1% longer to complete the compilation. EQFS incurs less than 5% overhead versus UFS or LUFS in terms of system time. These results show that EQFS imposes very little performance overhead, and does not limit file system scalability for realistic application workloads such as a large parallel compilation.
The performance of EQFS when doing the compile from /ehome is slightly worse than when doing the compile from /home because the source files are located in the underlying persistent directory. As a result, LOOKUP operations for uncached entries from /ehome will cause a lookup in both underlying directories. We analyzed the cost and frequency of various file operations for the compilation and found that while LOOKUP operations are the most frequent, accounting for almost half of all file operations, the total time spent doing LOOKUP operations was small. Since the same file is typically referenced multiple times during the build, requests are satisfied from the cache, resulting in little performance difference between compiling in /home versus /ehome.
For comparison purposes, we also measured the overhead of a null stacking layer and found that it incurred about 0.5% overhead when stacked on top of UFS or LUFS. This means that EQFS only imposes roughly 0.5% more overhead beyond the basic stacking costs, even though EQFS provides significant additional functionality. EQFS's low overhead is due in part to its effective use of the DNLC for vnode caching. Previously published results for similar compilation benchmarks on trivial stacking systems [31] that simply copy data between layers show a 14.4% increase in system time, significantly higher than what we measure for EQFS.
Table 2 shows the results for building the elastic file log. The results show that the entire log was created in only about 10 minutes using a cold cache. This indicates that the cost of building the elastic file log is small and should have little if any effect on system operation if run during off-peak hours. Table 2 also shows that the entire log was created in less than three minutes when using a warm cache. In practice, we expect actual numbers to be closer to those of a cold cache.
Table 3 shows the results of running the elastic file cleaning benchmark to clean 5 GB of disk space. The entire cleaning process took less than two minutes. Compared to the time it took to scan the disk and build the elastic file log, the overhead of cleaning is more than five times less, which shows the benefit of using the log for cleaning. In the absence of the elastic file log, removing the same set of data would have involved scanning the entire disk in order to find candidate files, which would have taken significantly longer. As expected, the figures indicate that the job is primarily I/O bound, with user and system times amounting to a mere fraction of the completion time.
The cleaning cost is low enough that rubberd may be run multiple times during the course of a day without much overhead. For instance, if rubberd were run once an hour, the rubberd would only need three percent of the time to clean 120 GB of disk space a day. It is unlikely that this much storage space would need to be reclaimed daily for most installations, so that rubberd cleaning overhead in practice would typically be even lower.
Table 4 shows the completion time for executing our large Solaris compile benchmark while rubberd is running. These results measure the impact of running rubberd cleaning on the Solaris compilation by comparing the compilation completion times when rubberd is not running, when rubberd is running at low priority, and when rubberd is running at normal priority.
Comparing with the Solaris compilation results without rubberd running, we observe a 3.5% degradation in completion time when rubberd is running at low priority, and a 4% degradation when running at regular priority. Running rubberd as a lower priority job does not make a large difference, primarily since both jobs are I/O bound, hence CPU scheduling priority has a very small impact on completion time. Furthermore, we observe that there are numerous lull times during a regular system's operation in which it would be possible to schedule rubberd to run with an even lower impact on system operation [6].
Overall, however, we observe that the impact of rubberd running even once an hour with a conservatively large amount of data to remove does not significantly hamper normal system operation. It is also important to note that as these files are temporary they would be removed anyhow; rubberd provides the added convenience of automatically doing so when disk space becomes low and before the disk fills up and hampers user productivity.