To provide a mechanism for reclaiming disk space used by elastic files when the disk becomes too full, we developed rubberd, a user-level space reclamation agent that leverages the separate elastic file storage and quota functionality provided by EQFS. Rubberd is a highly configurable cleaning agent, and its behavior can be set by the administrator, and also in part by the users of the system.
System administrators can specify the location of the elastic file system root, and parameters for describing the disk utilization characteristics required to start and stop cleaning operations and determine the rate of cleaning operations. The start cleaning threshold is the percentage of total disk space above which rubberd will start cleaning elastic files. The stop cleaning threshold is the percentage of total disk space below which rubberd will stop cleaning elastic files. The disk usage sampling interval is the amount of time that rubberd waits before it checks if the total disk usage is above the start cleaning threshold. System administrators can also choose whether or not to allow users to specify their own policies for determining the ordering in which elastic files are removed.
When reclaiming disk space, rubberd works in conjunction with the EQFS quota system to identify users who are over their quota limits. By default, rubberd removes elastic files from users who are over their quota in proportion to how much each user is over quota.
Note that rubberd only removes elastic files from users whose total disk space consumption, including both persistent and elastic usage, is over quota. If a user is consuming a large amount of elastic space but is below quota, none of that user's elastic files will be removed. In the absence of a user-specified removal policy, rubberd will remove elastic files from a given user in order of least recent file access time first.
Section 4.1 describes the rubberd cleaning mechanisms that enable rubberd to efficiently support a wide-range of cleaning policies. Section 4.2 describes the mechanism by which users can select the order of removal for elastic files to be cleaned. Section 4.3 describes the default rubberd proportional cleaning algorithm we use.
The key goal in the design of rubberd was to efficiently support a wide-range of removal policies provided by the system administrator or users without adversely impacting normal file operations. For example, when rubberd wakes up periodically, it must be able to quickly determine if the file system is over the start cleaning threshold. If the system is over the threshold, rubberd must be able to locate all elastic files quickly because those files are candidates for removal. Moreover, depending on the policy, rubberd will also need to find out certain attributes of elastic files, such as a file's owner, size, last access time, or name.
To meet this goal, rubberd was designed as a two-part system that separates obtaining file attributes from the actual cleaning process. Rubberd scans the file system nightly for all elastic files under /elastic to build a lookup log of information about the elastic files and their attributes. This log serves as a cache that rubberd then uses to lookup file attributes to determine what files to clean when the file system is over the start cleaning threshold. The log can be stored in a database, or a file or set of files. The prototype rubberd that we built used per-user linear log files that are created in parallel for faster completion time. We chose this approach over using popular databases such as NDBM or DB3 primarily for the sake of simplicity.
Rubberd's nightly scanning is analogous to other system processes such as backup daemons or GNU updatedb [15] that are already widely used and do nightly scans of the entire file system. Because rubberd does a full scan of elastic files, it can obtain all the information it may need about file attributes. Rubberd does not require any additional state to be stored on normal file operations, which would impact the performance of these operations. Since the vast majority of files created typically have short lifetimes of a few seconds[8,18,29], rubberd also avoids wasting time keeping track of file attributes for files that will no longer exist when the file system cleaning process actually takes place. Although the cleaning log will not have information on files just recently created on a given day, such recent files typically consume a small percentage of disk space [8]. Furthermore, we expect that most removal policies, including the default removal policy, will remove older files that have not been accessed recently.
When rubberd cleans, it uses the files in the log when applying a cleaning policy and searches the log for files that match the desired parameters (owner, creation time, name, size, etc.). By default, rubberd uses a disk usage sample interval of one hour so that it may reuse the log 23 times before another file system scan occurs. Since our lookup log is updated nightly at a time of least system activity, rubberd also initiates a cleanup check right after the log is updated. Because the log is by default updated only once a day, it is possible that rubberd could run out of elastic files in the log to clean while the disk utilization is still above the stop cleaning threshold. In this case, rubberd will initiate a more expensive full scan of the /elastic directory to update the elastic files log and restart the cleaning phase using this updated log. In this way, rubberd is able to optimize the common case cleaning using the log while limiting the need to do recursive scans of /elastic only as a last resort.
Normally, the rubberd cleaner simply runs as a low priority process to minimize its impact on other activities in the system; a progress-based regulation approach could also be used [6]. However, if the system is sufficiently busy that the rubberd cleaner does not complete before its next scheduled cleanup check, the priority of rubberd is raised to that of a system-level process to ensure that the cleaning process is given enough time to run. Rubberd cleaning can also be initiated by an administrator by sending a signal to the cleaning process, presumably because the administrators determined that cleaning is needed right away. In this case, the cleaner is also run at a higher system-level priority.
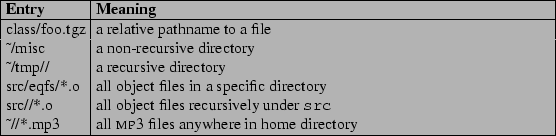
If the system administrator has allowed users to determine their own removal policies, users are then allowed to use whatever policy they desire for determining the order in which files are removed. A user-defined removal policy is simply a file stored in /var/spool/rubberd/username. The file is a newline-delimited list of file and directory names or simple patterns thereof, designed to be both simple and flexible to use. Each line can list a relative or absolute name of a file or directory. A double-slash (//) syntax at the end of a directory name signifies that the directory should be scanned recursively. In addition, simple file extension patterns could be specified. Table 1 shows a few examples and explains them.
Management of this removal policy file is done similarly to how crontab manages per-user cron jobs. A separate user tool allows a user to add, delete, or edit their policy file -- as well as to install a new policy from another source file. The tool verifies that any updated policy conforms to the proper syntax. This tool also includes options to allow users to initialize their default policy file to the list of all their elastic files, optionally sorted by name, size, modification time, access time, or creation time.
Rubberd's default removal policy proportionally distributes the amount
of data to be cleaned based on the amount by which users exceed their
quota limits. Rubberd is flexible enough that many other cleaning algorithms
and policies could also be used, but due to space constraints, a detailed
discussion of different cleaning algorithms and policies is beyond
the scope of this paper. Rubberd's default proportional share
cleaning behavior is provided by a simple algorithm that is easy to
implement. When rubberd wakes up every sample interval, it begins by
checking the current disk usage on the system. If the usage is over
the start cleaning threshold ![]() , rubberd calculates the total
amount of disk space to clean (
, rubberd calculates the total
amount of disk space to clean (![]() ) as follows:
) as follows:
| (1) |
Next, rubberd finds the amount of elastic disk usage over quota for
each user (![]() ). This value is retrieved from the quota system, by
querying it for the user's current quota usage based on the user's UID
for persistent disk usage, the corresponding shadow UID for elastic
disk usage, and comparing the sum of both usage values to the user's
actual fixed quota. Rubberd sums all
). This value is retrieved from the quota system, by
querying it for the user's current quota usage based on the user's UID
for persistent disk usage, the corresponding shadow UID for elastic
disk usage, and comparing the sum of both usage values to the user's
actual fixed quota. Rubberd sums all ![]() values for all
over-the-quota users into
values for all
over-the-quota users into ![]() . Then, rubberd computes the
portion of disk space that should be cleaned from each user (
. Then, rubberd computes the
portion of disk space that should be cleaned from each user (![]() ) as
follows:
) as
follows:
| (2) |
Before rubberd can begin to remove users' files, it decides the order
in which the files will be removed. Rubberd removes files as long as
the total sum of removed files is less than ![]() . First, rubberd
removes files in the order they are listed in the user's custom
policy file. If the policy file does not exist, or all files
corresponding to the policy file have been removed, rubberd will then
use the system default removal policy for removing more elastic files
if more files need to be removed. The system default policy is to
remove files by earliest access time first, which is based on the
assumption that these files are generally the least likely files to be
used again in the future.
. First, rubberd
removes files in the order they are listed in the user's custom
policy file. If the policy file does not exist, or all files
corresponding to the policy file have been removed, rubberd will then
use the system default removal policy for removing more elastic files
if more files need to be removed. The system default policy is to
remove files by earliest access time first, which is based on the
assumption that these files are generally the least likely files to be
used again in the future.