This section details the design and implementation of four sample file systems we wrote using Wrapfs:
These examples are merely experimental file systems intended to illustrate the kinds of file systems that can be written using Wrapfs. We do not consider them to be complete solutions. There are many potential enhancements to our examples.
Lofs2 provides access to a directory of one file system from another, without using symbolic links. It is most often used by automounters to provide a consistent name space for all local and remote file systems, and by chroot-ed processes to access portions of a file system outside the chroot-ed environment
This trivial file system was actually implemented by removing unnecessary code from Wrapfs. A loopback file system does not need to manipulate data or file names. We removed all of the hooks that called encode_data, decode_data, encode_filename, and decode_filename. This was done to improve performance by avoiding unnecessary copying.
Before we embarked on a strong encryption file system, described in the next section, we implemented one using a trivial encryption algorithm. We decided at this stage to encrypt only file data. The implementation was simple: we filled in encode_data and decode_data with the same rot13 algorithm (since the algorithm is symmetric).
Cryptfs uses Blowfish[17] -- a 64 bit block cipher that is fast, compact, and simple. We used 128 bit keys. Cryptfs uses Blowfish in Cipher Block Chaining (CBC) mode, so we can encrypt whole blocks. We start a new encryption sequence for each block (using a fixed Initialization Vector, IV) and encrypt whole pages (4KB or 8KB) together. That is, within each page, bytes depend on the preceding ones. To accomplish this part, we modified a free reference implementation (SSLeay) of Blowfish, and put the right calls to encrypt and decrypt a block of data into encode_data and decode_data, respectively.
Next, we decided to encrypt file names as well (other than ``.'' and ``..'' so as to keep the lower level file system intact). Once again, we placed the right calls to encrypt and decrypt file names into the respective encode_filename and decode_filename functions. Applying encryption to file names may result in names containing characters that are illegal in Unix file names (such as nulls and forward slashes ``/''). To solve this, we also uuencode file names after encrypting them, and uudecode them before decrypting them.
Key management was the last important design and implementation issue for Cryptfs. We decided that only the root user will be allowed to mount an instance of Cryptfs, but could not automatically encrypt or decrypt files. We implemented a simple ioctl in Cryptfs for setting keys. A user tool prompts for a passphrase and using that ioctl, sends an MD5 hash of the passphrase to a mounted instance of Cryptfs. To thwart an attacker who gains access to a user's account or to root privileges, Cryptfs maintains keys in an in-memory data structure that associates keys not with UIDs alone but with the combination of UID and session ID. To succeed in acquiring or changing a user's key, an attacker would not only have to break into an account, but also arrange for his processes to have the same session ID as the process that originally received the user's passphrase. Since session IDs are set by login shells and inherited by forked processes, a user would normally have to authorize themselves only once in a shell. From this shell they could run most other programs that would work transparently and safely with the same encryption key.
Details of the design and implementation of Cryptfs are available as a separate technical report[23].
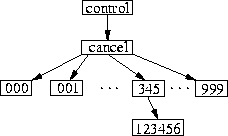
Busy traditional Usenet news servers could have large directories containing many thousands of articles in directories representing very active newsgroups such as control.cancel and misc.jobs.offered. Unix directory searches are linear and unsorted, resulting in significant delays processing articles in these large newsgroups. We found that over 88% of typical file system operations that our departmental news server performs are for looking up articles. Usenetfs improves the performance of looking up and manipulating files in such large flat directories, by breaking the structure into smaller directories.
Since article names are composed of sequential numbers, Usenetfs takes
advantage of this to generate a simple hash function. After some
experimentation, we decided to create a hierarchy consisting of one thousand
directories as depicted in Figure 5.
Additionally, we decided to use a seldom used mode bit for directories, the setuid bit, to flag a directory as managed by Usenetfs. Using this bit allows the news administrator to control which directory is managed by Usenetfs and which is not, using a simple chmod command.
The implementation of Usenetfs concentrated in two places. First, we implemented the encode_filename and decode_filename to convert normal file names into their extended deeper-hierarchy forms, and back (but only for directories that were flagged as managed by Usenetfs). Second, we updated the readdir function to iterate over all possible subdirectories from 000 to 999, and perform a (smaller) directory read within each one.
Details of the design and implementation of Usenetfs are available as a separate technical report[22].