In a stacking environment that supports SCAs, data offsets may change arbitrarily. An efficient mapping is needed that can tell where the starting offset of the encoded data is for a given offset in the original file. We call this mapping the index table.
The index table is stored in a separate file called the index file, as shown in Figure 2. This file serves as the fast meta-data index into an encoded file. For a given data file F, we create an index file called F.idx. Many file systems separate data and meta data; this is done for efficiency and reliability. Meta-data is considered more important and so it gets cached, stored, and updated differently than regular data. The index file is separate from the encoded file data for the same reasons and to allow us to manage each part separately and simply.
 |
Our system encodes and decodes whole pages or their multiples--which maps well to file system operations. The index table assumes page-based operations and stores offsets of encoded pages as they appear in the encoded file.
Consider an example of a file in a compression file system. Figure 3 shows the mapping of offsets between the upper (original) file and the lower (encoded) data file. To find out the bytes in page 2 of the original file, we read the data bytes 3000-7200 in the encoded data file, decode them, and return to the VFS that data in page 2.
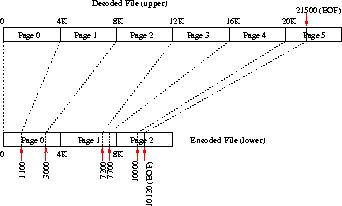 |
To find out which encoded bytes we need to read from the lower file, we consult the index file, shown in Table 1. The index file tells us that the original file has 6 pages, that its original size is 21500 bytes, and then it lists the ending offsets of the encoded data for an upper page. Finding the lower offsets for the upper page 2 is a simple linear dereferencing of the data in the index file; we do not have to search the index file linearly. Note that our design of the index file supports both 32-bit and 64-bit file systems, but the examples we provide here are for 32-bit file systems.
|
The index file starts with a word that encodes flags and the number of pages in the corresponding original data file. We reserve the lower 12 bits for special flags such as whether the index file encodes a file in a 32-bit or a 64-bit file system, whether fast tails were encoded in this file (see Section 4.2), etc. The very first bit of these flags, and therefore the first bit in the index file, determines if the file encoded is part of a 32-bit or a 64-bit file system. This way, just by reading the first bit we can determine how to interpret the rest of the index file: 4 bytes to encode page offsets on 32-bit file systems or 8 bytes to encode page offsets on 64-bit file systems.
We use the remaining 20 bits (on a 32-bit file system) for the number of pages because 220 4KB pages (the typical page size on i386 and SPARCv8 systems) would give us the exact maximum file size we can encode in 4 bytes on a 32-bit file system, as explained next; similarly 252 4KB pages is the exact maximum file size on a 64-bit file system.
The index file also contains the original file's size in the second word. We store this information in the index file so that commands like ls -l and others using stat(2) would work correctly; a process looking at the size of the file through the upper level file system would get the original number of bytes and blocks. The original file's size can be computed from the starting offset of the last data chunk in the encoded file, but it would require decoding the last (possibly incomplete) chunk (bytes 10000-10120 in the encoded file in Figure 3) which can be an expensive operation depending on the SCA. Storing the original file size in the index file is a speed optimization that only consumes one more word--in a physical data block that most likely was already allocated.
The index file is small. We store one word (4 bytes on a 32-bit file system) for each data page (usually 4096 bytes). On average, the index table size is 1024 times smaller than the original data file. For example, an index file that is exactly 4096 bytes long (one disk block on an Ext2 file system formatted with 4KB blocks) can describe an original file size of 1022 pages, or 4,186,112 bytes (almost 4MB).
Since the index file is relatively small, we read it into kernel memory as soon as the main file is open and manipulate it there. That way we have fast access to the index data in memory. The index information for each page is stored linearly and each index entry typically takes 4 bytes. That lets us compute the needed index information simply and find it from the index table using a single dereference into an array of 4-byte words (integers). To improve performance further, we write the final modified index table only after the original file is closed and all of its data flushed to stable media.
The size of the index file is less important for SCAs which increase the data size, such as unicoding, uuencoding, and some forms of encryption. The more the SCA increases the data size, the less significant the size of the index file becomes. Even in the case of SCAs that decrease data size (e.g., compression) the size of the index file may not be as important given the savings already gained from compression.
Since the index information is stored in a separate file, it uses up one more inode. We measured the effect that the consumption of an additional inode would have on typical file systems in our environment. We found that disk data block usage is often 6-8 times greater than inode utilization on disk-based file systems, leaving plenty of free inodes to use. To save resources even further, we efficiently support zero-length files: a zero-length original data file is represented by a zero-length index file.
For reliability reasons, we designed the index file so it could be recovered from the data file in case the index file is lost or damaged (Section 5.) This offers certain improvements over typical Unix file systems: if their meta-data (inodes, inode and indirect blocks, directory data blocks, etc.) is lost, it rarely can be recovered. Note that the index file is not needed for our system to function: it represents a performance enhancing tool. Without the index file, size-changing file systems would perform poorly. Therefore, if it does not exist (or is lost), our system automatically regenerates the index file.