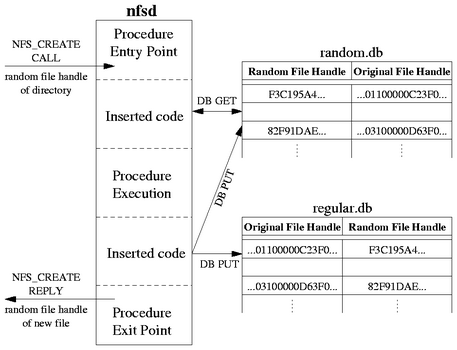
| Length | Bytes | Field Name | Meaning | Typical Values |
| 1 | 1 | fb_version | NFS version | Always 1 |
| 1 | 2 | fb_auth_type | Authentication method | Always 0 |
| 1 | 3 | fb_fsid_type | File system ID encoding method | Always 0 |
| 1 | 4 | fb_fileid_type | File ID encoding method | Always either 0, 1, or 2 |
| 4 | 5-8 | xdev | Major/Minor number of exported device | Major number 3 (IDE), 8 (SCSI) |
| 4 | 9-12 | xino | Export inode number | Almost always 2 |
| 4 | 13-16 | ino | Inode number | 2 for /, 19 for /home/foo |
| 4 | 17-20 | gen_no | Generation number | 0xFF16DDF1, 0x3F6AE3C0 |
| 4 | 21-24 | par_ino_no | Parent's inode number | 2 for /, 19 for /home |
| 8 | 25-32 | Padding for NFSv2 | Always 0 | |
| 32 | 33-64 | Unused by Linux | ||
| Length | Bytes | Field Name | Meaning | Typical Values |
| 8 | 1-8 | fsid | File system ID | 0x3F607F14 1C47F86E |
| 2 | 9-10 | fid_len | Length of the rest of the structure | Always 12 |
| 2 | 11-12 | fid_reserved | Word alignment | Always 0 |
| 4 | 13-16 | ufid_ino | Inode Number | 3, 47 |
| 4 | 17-20 | ufid_gen | Inode Generation Number | 0x0C8F960C, 0x9CFF85C7 |
| 12 | 21-32 | Padding for NFSv2 | Always 0 | |
| 32 | 33-64 | Unused by FreeBSD | ||
| Length | Bytes | Field Name | Meaning | Typical Values |
| 4 | 1-4 | fh_fsid[0-3] | Derived from device major/minor numbers. | 0x01980000 |
| 4 | 5-8 | fh_fsid[4-7] | File system type | 2 for UFS |
| 2 | 9-10 | fh_len | size of fh_data | Always 10 |
| 2 | 11-12 | fh_data[0-1] | Make the inode number word aligned | Always 0 |
| 4 | 13-16 | fh_data[2-5] | Inode number | 4 for /, 37 for /home/foo |
| 4 | 17-20 | fh_data[6-9] | Generation number | 0x72D2970C, 0x2482AAF4 |
| 2 | 21-22 | fh_xlen | size of fh_xdata | Always 10 |
| 2 | 23-24 | fh_xdata[0-1] | Make the inode number word aligned | Always 0 |
| 4 | 25-28 | fh_xdata[2-5] | Inode number of the export point | 4 for / |
| 4 | 29-32 | fh_xdata[6-9] | Generation number of the export point | 0x72D2970C |
| 32 | 33-64 | Unused by Solaris | ||
| 1Gbps | 100Mbps | |
| Guess attempts/sec | 13,119 | 6,996 |
| Guess Mbps sent | 17.0 | 8.8 |
| Guess Mbps received | 7.8 | 3.9 |
| Ping Mbps sent | 23.0 | 20.0 |
| Ping Mbps received | 23.0 | 14.0 |
| NFS Operation | SFS 3.0 NFSv3 |
| LOOKUP | 27% |
| READ | 18% |
| WRITE | 9% |
| GETATTR | 11% |
| READLINK | 7% |
| READDIR | 2% |
| CREATE | 1% |
| REMOVE | 1% |
| FSSTAT | 1% |
| SETATTR | 1% |
| READDIRPLUS | 9% |
| ACCESS | 7% |
| COMMIT | 5% |
| VAN | ENH-32 | |
| Elapsed time | 151.9s | 156.0s |
| System time | 37.7s | 37.6s |
| Wait time | 39.2s | 49.9s |