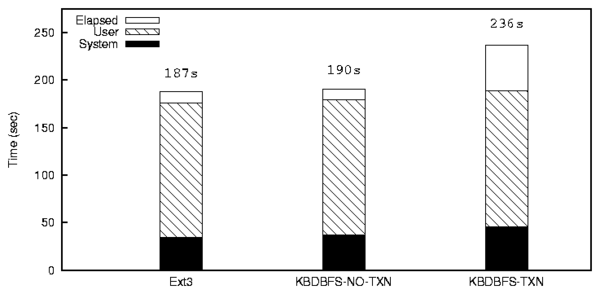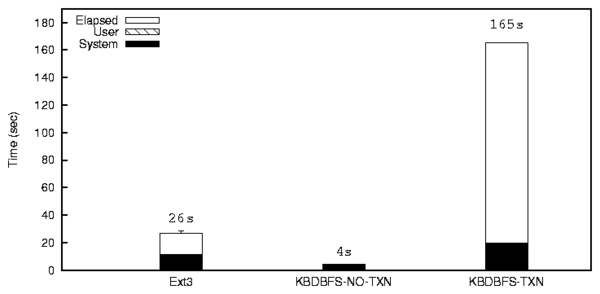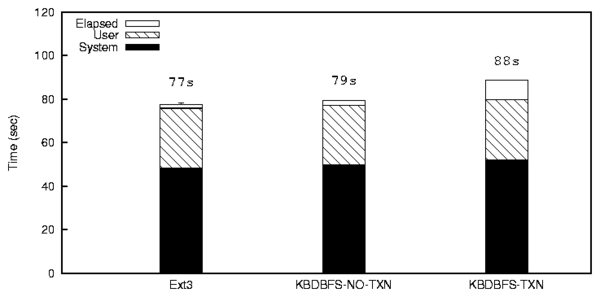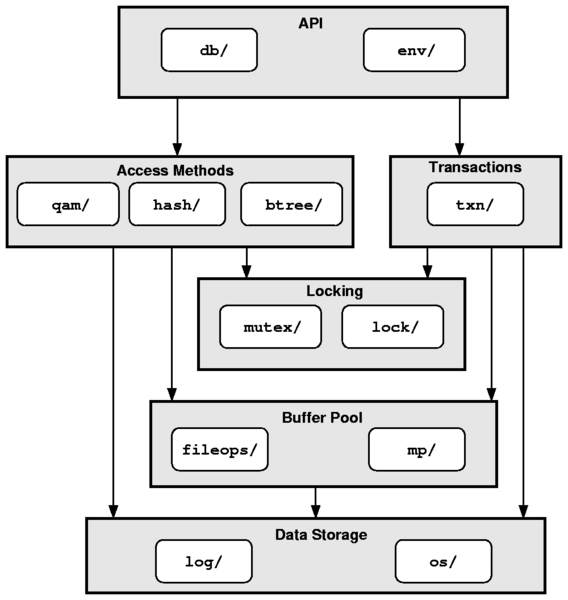
| File or Directory | Add | Del | Chg |
| db/ | 4 | - | 2 |
| env/ | 3 | - | 8 |
| qam/ | - | - | - |
| hash/ | - | - | - |
| btree/ | - | - | - |
| txn/ | - | - | - |
| mutex/ | 34 | 1 | 6 |
| lock/ | 42 | 10 | 92 |
| fileops/ | - | - | - |
| mp/ | - | - | - |
| log/ | - | - | - |
| os/ | 528 | 10 | 370 |
| dbinc/ | 71 | - | 55 |
| db.h | 208 | 7 | 44 |
| Total = 1,495 | 890 | 28 | 577 |
| Inode namespace functions | 2,131 | - | - |
| Shared memory operations | 640 | - | - |
| Assorted wrapper functions | 449 | - | - |
| Quicksort | 405 | - | - |
| Long division | 419 | - | - |
| Random number generator | 155 | - | - |
| Grand Total = 5,694 | - | - | - |
| Final Code Size = 155,789 | - | - | - |
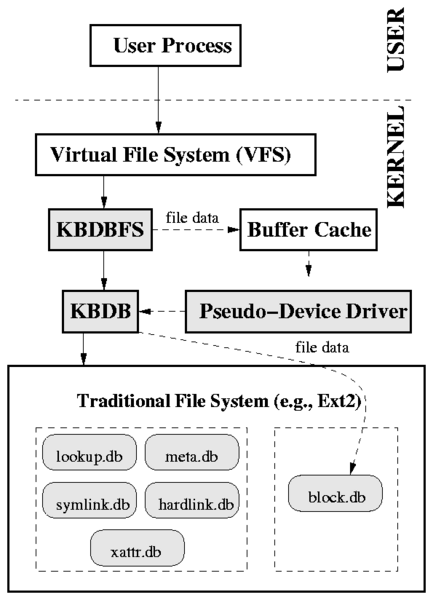
| Database | Key | Value |
| lookup.db | Parent inode number || Child's name | Child inode number |
| meta.db | Inode number | Inode meta-data (e.g., size, atime, owner) |
| block.db | Inode number || Block index | Block's data |
| hardlink.db | Inode number | Parent inode number || Name |
| symlink.db | Inode number | Symlink value |
| xattr.db | Inode number || EA name | EA value |