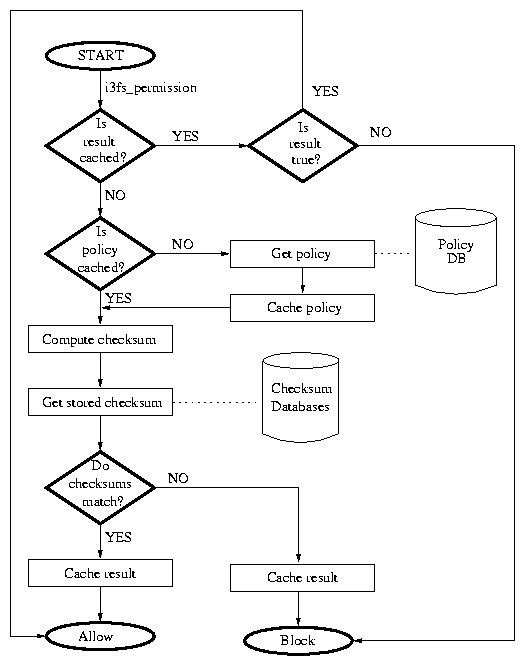
| p | Permission and file mode bits |
| i | Inode Number |
| n | Number of Links |
| u | User id of the owner |
| g | Group id of the owner |
| s | File size |
| d | ID of the device on which the inode resides |
| b | Number of blocks allocated |
| a | Access time |
| m | Modification time |
| c | Inode change time |
| D | Checksum file data |
| I | Inherit the policies for new files |
| Database | Key | Value |
| policydb | inode# | Policy bits, freq# |
| datadb | inode#, page# | Checksum value |
| metadb | inode# | Checksum value |
| accessdb | inode# | Counter value# |